It’s all anyone is talking about right now: Sakana AI launched Fugu (and its Fugu Ultra variant), and half the tech press is presenting it as the system that “matches Fable 5 and Mythos.” Before that headline sticks in your head, let me put one thing up front: Fugu is not an LLM. And understanding that completely changes how you should read the comparison.
What Fugu actually is
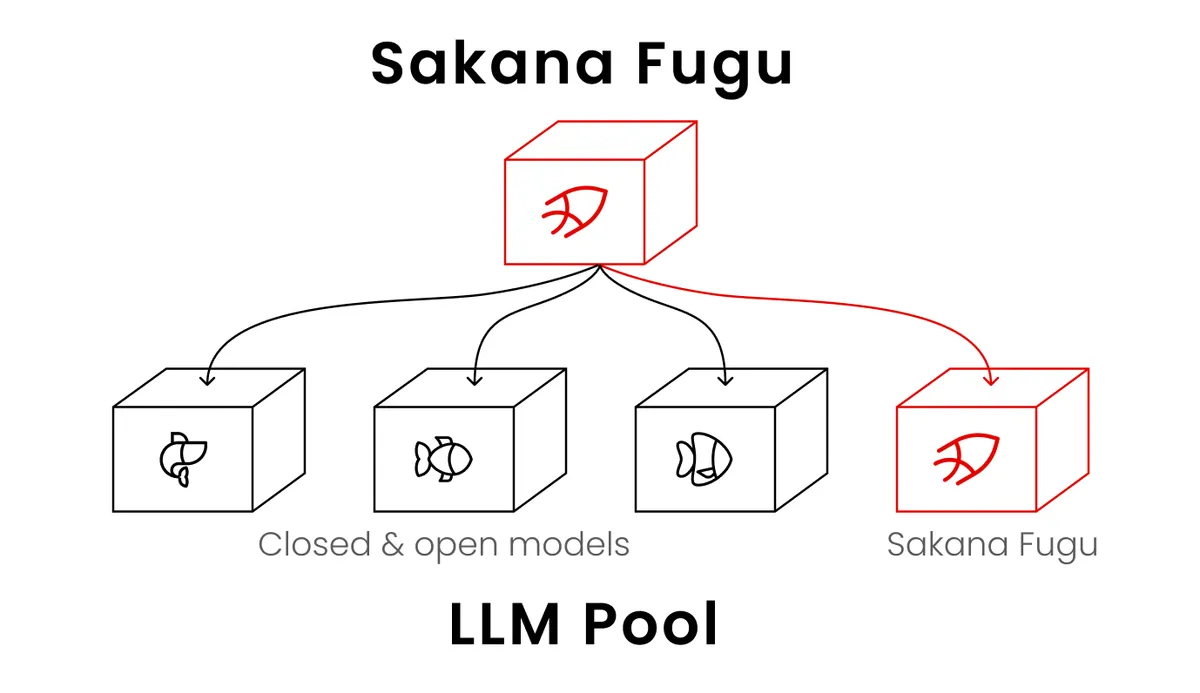
Fugu is a multi-agent orchestrator. It is not a frontier model trained from scratch by Sakana: it is a system that takes your task, decides how to split it, and routes it to a swappable pool of frontier models —the usual suspects, Opus 4.8, GPT-5.5 and friends— behind a single API. The Verge summed it up with perfect sarcasm: it promises “frontier-level performance”… by using frontier models.
Sakana’s own piece seems to be a relatively small router (people mention a ~7B model) that coordinates the big ones. It is a legitimate approach and, I’ll admit it, interesting: instead of training a monolith, you orchestrate collective intelligence from models that already exist. For certain complex tasks, where you can spread subproblems across several specialists, it makes complete sense.
Why the Mythos comparison is misleading
Here is my main objection. When you read “Fugu matches Mythos on benchmarks,” it sounds like a brand-new competitor at Anthropic’s level just appeared. But that is not what happened. Fugu matches those numbers by orchestrating other frontier models. It is not a rival to Mythos: it is a wrapper that, among others, could call Mythos.
In fact, I’d bet on it: when Mythos becomes available again, it will be in the catalog Fugu uses. Comparing an orchestrator against one of the very models the orchestrator will want to invoke is not a fight between equals. It is comparing the conductor with one of the musicians.
The catch: slower and more expensive
And this is where the approach takes its toll. Orchestrating several frontier models for a single task has two costs that cannot be hidden:
- Latency. Real-world tests have reported waits of up to 30 minutes for a response. When you coordinate several models, wait, recombine and validate, the clock keeps running. There are reports that Fugu Ultra lags in real coding tests despite looking good on benchmarks.
- Cost. This is simple arithmetic: if a task fires calls to Opus 4.8 and GPT-5.5 and others, you pay for all of them. By definition, that is more expensive than using any one of those models independently. The orchestrator doesn’t make anything cheaper; it adds up.
Plainly: you pay more and wait longer, in exchange for a router deciding which model to use for you. For a lot of people, that trade-off doesn’t pay off.
When it does make sense
I don’t want to be unfair, because I think the approach is valuable in its niche. Fugu shines when the task is genuinely complex and decomposable: workflows where splitting subtasks across specialized models adds more than the extra latency costs. It also solves a real vendor lock-in pain: a single API up front, swappable models behind it. If your priority is not being tied to a single provider, that carries real strategic weight.
My verdict
Fugu is an interesting orchestration experiment, not a new frontier model, and it’s worth not confusing the two. For complex, decomposable tasks, or for anyone wanting to shield themselves against lock-in, it is a tool to watch. But for day-to-day use it is slower and more expensive than going straight to Opus or GPT, and the benchmarks it “matches” are achieved by leaning on those very models. And let’s not forget: when Mythos returns, it will end up inside Fugu’s catalog. That sentence alone makes clear what each thing is.


