Estos días no se habla de otra cosa: Sakana AI lanzó Fugu (y su variante Fugu Ultra) y media prensa tech lo presenta como el sistema que “iguala a Fable 5 y Mythos”. Antes de que el titular se quede en tu cabeza, quiero poner una cosa por delante: Fugu no es un LLM. Y entender eso cambia por completo cómo deberías leer la comparación.
Qué es realmente Fugu
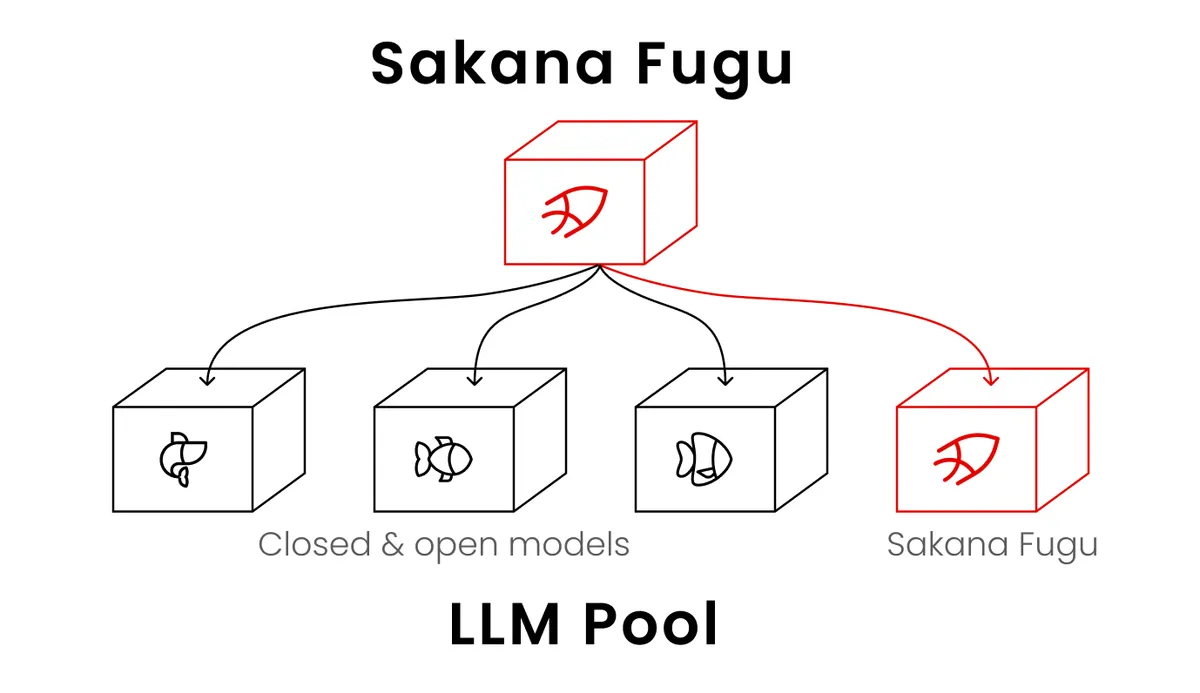
Fugu es un orquestador multi-agente. No es un modelo frontera entrenado desde cero por Sakana: es un sistema que recibe tu tarea, decide cómo trocearla y la enruta a un pool intercambiable de modelos frontera —los de siempre, Opus 4.8, GPT-5.5 y compañía— detrás de una única API. The Verge lo resumió con sarcasmo perfecto: promete “rendimiento de nivel frontera”… usando modelos frontera.
La pieza propia de Sakana parece ser un router relativamente pequeño (se habla de un modelo de ~7B) que coordina a los grandes. Es un enfoque legítimo y, lo admito, interesante: en lugar de entrenar un monolito, orquestas inteligencia colectiva con modelos que ya existen. Para ciertas tareas complejas, donde puedes repartir subproblemas entre varios especialistas, tiene todo el sentido.
Por qué la comparación con Mythos es engañosa
Aquí está mi reparo principal. Cuando lees “Fugu iguala a Mythos en benchmarks”, suena a que apareció un competidor nuevo al nivel de Anthropic. Pero no es eso lo que pasó. Fugu iguala esos números orquestando otros modelos frontera. No es un rival de Mythos: es un envoltorio que, entre otros, podría llamar a Mythos.
De hecho, lo doy casi por seguro: cuando Mythos vuelva a estar disponible, estará en el catálogo que Fugu use. Comparar un orquestador contra uno de los modelos que el propio orquestador querrá invocar no es una pelea entre iguales. Es comparar al director de orquesta con uno de sus músicos.
El problema: más lento y más caro
Y aquí es donde el enfoque pasa factura. Orquestar varios modelos frontera para una sola tarea tiene dos costes que no se pueden esconder:
- Latencia. En pruebas reales se han reportado esperas de hasta 30 minutos para una respuesta. Cuando coordinas varios modelos, esperas, recombinas y validas, el reloj corre. Hay reportes de que Fugu Ultra se queda atrás en pruebas de código reales pese a lucir bien en los benchmarks.
- Coste. Esto es simple aritmética: si una tarea dispara llamadas a Opus 4.8 y a GPT-5.5 y a otros, pagas por todos ellos. Por definición, eso sale más caro que usar cualquiera de esos modelos de forma independiente. El orquestador no abarata nada; suma.
Dicho claro: pagas más y esperas más, a cambio de que un router decida por ti qué modelo usar. Para mucha gente, ese intercambio no compensa.
Cuándo sí tiene sentido
No quiero ser injusto, porque el approach me parece valioso en su nicho. Fugu brilla cuando la tarea es genuinamente compleja y descomponible: flujos donde repartir subtareas entre modelos especializados aporta más de lo que cuesta la latencia extra. También resuelve un dolor real de vendor lock-in: una sola API por delante, modelos intercambiables por detrás. Si tu prioridad es no atarte a un único proveedor, eso tiene un peso estratégico de verdad.
Mi veredicto
Fugu es un experimento interesante de orquestación, no un nuevo modelo frontera, y conviene no confundir las dos cosas. Para tareas complejas y descomponibles, o para quien quiera blindarse contra el lock-in, es una herramienta a vigilar. Pero para el uso del día a día es más lento y más caro que ir directo a Opus o a GPT, y los benchmarks que “iguala” los consigue apoyándose en esos mismos modelos. Y no lo olvidemos: cuando Mythos vuelva, acabará dentro del catálogo de Fugu. Esa frase, por sí sola, deja claro qué es cada cosa.


